'노래하는 TTS' ... 그런 이름의 연구과제를 어깨너머로 본 적이 있다. (TTS는 Text-To-Speech, 즉 음성합성이라는 뜻이다) 당시 소속되어 있던 연구실 뿐만 아니라 국내에서만도 몇몇 학교와 연구기관에서 연구하던 주제였다.
어느 정도 알아들을 수 있는 걸음마 수준의 음성합성기였지만, 떡잎부터 보였던 문제 중 하나는 그 '소름끼치는 목소리'였다. 분명 100% 기계적으로 합성한 초기의 음성합성 방식이 아님에도 불구하고, 사람 목소리 중에서 다양하게 사용할 수 있는 '중립적인' 음원을 중심으로 sampling하다보니 아무래도 강약도 높낮이도 없는 건조한 목소리가 되기 마련이고, 그렇게 합성된 음성에는 "공동묘지에서 들리면 기절하겠다"든가 "연변 뉴스 아나운서가 있다면 이렇지 않을까"라든가 하는 소리가 늘상 따라다녔던 거다.
합성된 음성에 강약과 높낮이를 넣기 위한 대표적인 연구인 '노래하는 TTS' 연구과제는, 하지만 너무 많은 난관 - 노래는 음표만으로 이루어지는 게 아니라 많은 기법들이 동시에 적용되며, 게다가 악보에 나와있진 않지만 노래할 때 생기는 자연스러운 현상, 즉 발음이 뭉개지거나 평서문과 다른 곳에서 연음이 생기는 등을 고려해야 하는 점이 기존 음성합성 연구범위만으로는 해결하기 어려웠기에 순탄하게 진행되지도 뚜렷한 성과를 내지도 못했던 것 같다.
...
그건 그렇고, "파돌리기 송"이라고 들어봤는가? ㅡ_ㅡ;;;
중독성이 있네, 가사에 무슨 의미가 있네 하면서 한참을 인터넷에 돌아다녔던 동영상이고, 나도 무슨 일본 애니메이션 캐릭터를 가지고 장난친 거려니 하고 그냥 한번 보고 웃어넘겼던 동영상이다.
그런데, 같이 일했던 분이 알려준 블로그에 의하면, 이게 컴퓨터로 합성된 음악.. 그러니까 노래라고 한다. 관련된 동영상이며 캐릭터 이미지들을 찾아보니 과연 참 오타쿠 문화의 본산인 일본다운 기획이다 - 좋은 뜻도 나쁜 뜻도 포함해서 - 싶으면서도, 음성합성이라는 측면에서 봤을 때는 엄청난 발전이라는 생각도 들었다.

여기에 사용된 '노래 합성' S/W와 데이터베이스는 Yamaha의 Vocaloid라는 제품이다. 현재는 일본어와 영어를 제공한다지만, 사실 음운 기반의 합성 방식이므로 약간의 불편을 감수하면 어떤 언어로도 사용이 가능할 것으로 보인다.
잠깐 이 Vocaloid라는 S/W의 모습을 보면:
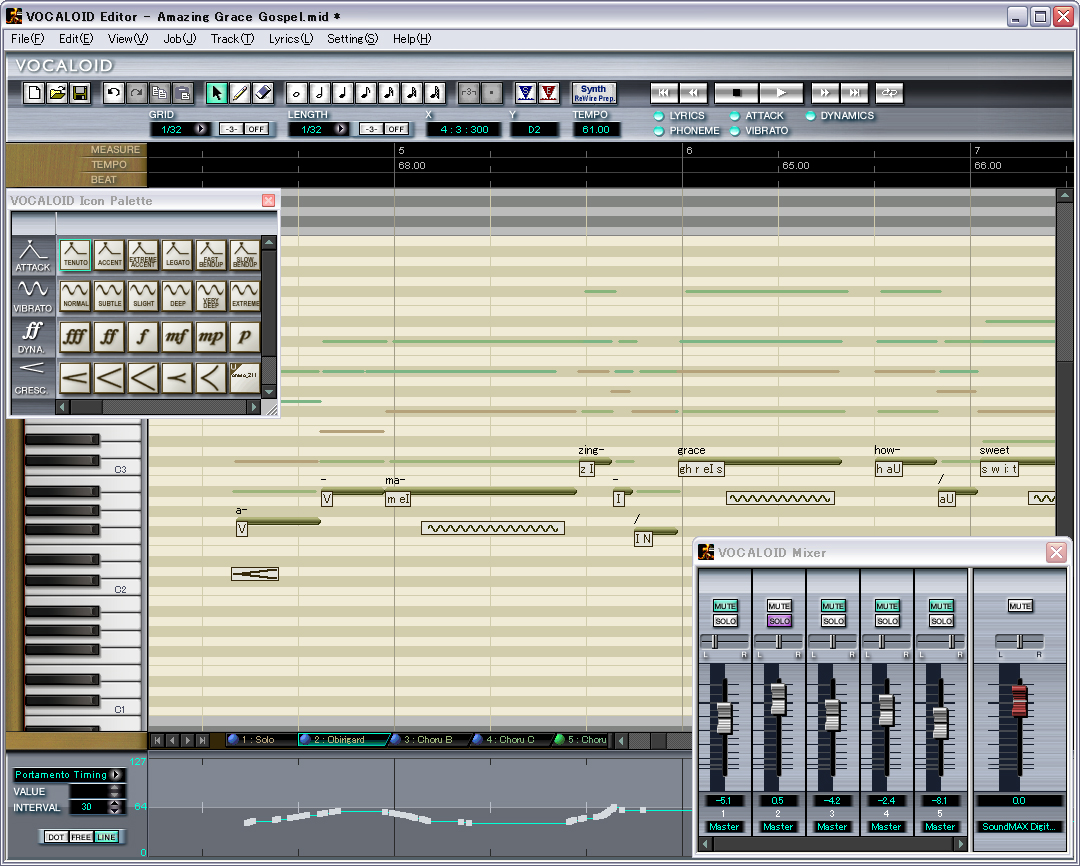
악보를 오선지에 그리는 대신 높낮이에 따른 시간 막대로 표시한 다음, 각각의 음에 해당하는 대목(단어 혹은 그 일부)을 입력하는 방식임을 알 수 있다. 각각의 단어에 해당하는 음소는 자동생성되지만, 필요에 따라 편집할 수도 있다고 한다. 뭐 여기까지는 기존의 '노래하는 TTS'들과 비슷하지만, Yamaha 다운 점이랄 수 있는 것은 역시 노래의 강약조절이나 vibration 같은 기법을 넣을 수 있도록 했다는 것이랄까. 이게 단지 몇가지 필터를 넣은 게 아니라, 노래의 다양한 패턴 중에서 자연스럽게 적용될 수 있도록 한 점이 돋보인다. 실제로 샘플 노래를 들어보면 단순히 특정 음에 맞춰 특정 발화를 주어진 길이만큼 하는 단순한 조합에 비해 훨씬 자연스럽다고 생각한다.
 invalid-file
invalid-file지난 1997년말 '사이버 가수'라는 타이틀을 처음으로 대대적으로 내세운 '아담'이라는 ... "그림"이 널리 회자된 적이 있다. 가수인 주제에 입 벌린 사진 하나 찾을 수 없는 이 친구는 사실 CG 캐릭터에 가까왔고, 실제 노래를 부른 가수는 따로 있었으니 실상은 '립싱크' 가수랄까. 사실 그건 1996년에 나온 일본의 '버추얼 아이돌'인 '다테 교코'도 마찬가지였고. 이런 기획들을 비판하며 "세계 최초의 100% 사이버 가수"라고 나온 싸이아트(SciArt)도 사실 Vocaloid를 적용한 사례라고 한다. (남의 S/W 갖다 쓰면서 잘도 세계 최초라는 말이 나왔다;;) 뭐 심지어는 로봇에 같은 립싱크 기술을 적용한 EveR-2 Muse도 비슷한 사례라 하겠다.




노래하는 가상의 캐릭터라니... Uncanny valley도 생각이 나고, 미래에는 인간은 토크쇼 등을 통해서 "캐릭터性"만을 담당하고 나머지는 모두 합성된 캐릭터(모습은 물론 대사까지도)가 할 거고 섣부른 예측을 했던 것도 생각나고, 뭐 이것저것 떠오르는 생각은 많다.
그러다가 문득, 오래 전에 읽은 기사가 묘하게 연결되어 버렸다.
진실은 이렇다. 가수들이 음반을 녹음할 때, 노래를 한번에 불러 녹음하는 경우는 거의 없다. 2~8마디씩 끊어 부른 뒤, 각 부분을 합쳐 한 덩어리의 노래를 만든다.
이를테면, ‘나는 너를 사랑해’라는 가사가 있다면, ‘나는’ ‘너를’ ‘사랑해’를 수없이 반복해 부른 후, 이 중에서 가장 좋은 소리가 나온 부분을 골라서 노래 한 곡을 완성하는 것이다. 물론 ‘사’ ‘랑’ ‘해’도 따로따로 ‘채집’이 가능하다. ‘찍어 붙이기’라 불리는 이 ‘짜깁기’ 편집 기법은 한국의 댄스곡 수준을 엄청나게 향상시킨 ‘비밀 병기’다.
한 가요 작곡가는 “신인급에 속하는 댄스가수는 보통 소절마다 100번씩 노래를 반복해서 부른다”며 “최악의 경우, 1000번씩 노래하는 댄스가수도 있다고 들었다”고 했다.
출처: 조선일보 <일부 신인, 한 소절 100번씩 녹음해 편집>
http://www.chosun.com/culture/news/200602/200602030471.html
Vocaloid를 통해서 음소단위로 자른 음성은 연결해서 노래를 만드는 것은, 음성 합성 기술을 음악이라는 장르에 맞게 확장한 것이다. 이 음성 합성 기술의 가장(?) 기초적인 적용은 concatenated speech synthesis, 즉 녹음된 말들을 적당히 - 어절 혹은 문장 단위로 - 끊어서 연결하는 방식이다. 그렇다면 사실 위의 기사에서 말한 일부 가수들의 모습은 오히려 Vocaloid보다 원시적인 음성... 아니, 노래 합성의 사례일 뿐이다.
그렇게 생각한다면, 어쩌면 이미 사이버 가수라든가 진짜 가수라든가 하는 경계는 사라지고 있는 게 아닐까. Kurzweil이 <The Age of Spiritual Machines>에서 예견했듯이, 기계와 인간의 경계는 이렇게 모르는 사이에 슬금슬금 허물어지고 있는 것 같다는 생각이 들었다. 어쩌면 연기뿐만 아니라, 가수라는 직업도 "캐릭터性"만 보여주고 실제 노래는 (심지어 춤도) 기계가 하게 되는 "끔찍한" 모습을 보게 될지도 모르겠다. 지금은 "끔찍해 보이는" 그 두 개체 사이의 연관관계는, 또 대중매체와 자본주의가 어떻게든 설명해내야 하겠지만.

