Conversation Works. 이건 지금은 인터넷 한 구석에 숨어있는, 내가 1999년 말 혹은 2000년 초에 만들었던 홈페이지의 제목이다. 대화형 에이전트 conversational agent 와 대화 모델링 dialogue modeling 이라는 것을 어깨 너머로나마 접하고나서, 그리고 한창 음성인식/음성합성과 Microsoft Agent 를 이용한 대화형 사용자 인터페이스 작업을 하고 있던 참이라, 요거 참 새롭다 싶어서 당시 빠져있던 JavaScript로 구현해 본 거였다. ^^*
이 홈페이지를 만들 때에도 물론 그랬고, 지금까지도 '인간의 대화'라는 것은 내가 끼고 사는 가장 큰 화두 중의 하나다.
태초(?)에 GUI가 있었을 때에는 "대화창 dialog pop-up"이 나와 과연 삭제를 할 것인가 말 것인가 하는 철학적인 질문에 대해 아주 단편적인 - Yes or No - 답변을 강요하던 시절도 있었지만, 이제는 음성인식이나 합성 기술의 발달로 인해 인간의 말을 문자로 바꾸고 문자를 말로 바꿀 수 있게 됐고, 자연어 처리 기술(NLP; natual language processing)이 발달함에 따라 문자로 입력된 말(단어, 문장, 문단, ...)의 구조와 약간의 의미를 알 수 있게 되었다. 즉 기계와 음성으로 대화를 한다는 것이 아주 불가능하지는 않게 된 거다.
하지만 그건 사실 위 홈페이지를 만들었던 1999년에도 10년째 가능했던 기술이고, 그 기술적 수준이 또다시 10년간 많이 발전했음에도 불구하고 상용화를 목표로 한다면 아직 멀고도 먼 갈 길이 남아있는 기술이다. (이 말은 1~2년 내로 '비겁한 변명'이 될 소지가 크다 ;ㅁ; )

그런데, 사실 인간과 시스템이 의사소통하는 방법에는 버튼을 클릭하는 것과 음성으로 대화하는 것 사이에도 수많은 대안들이 있다. 이를테면 음성이 아닌 '문자'로 대화하는 방법이 있을 수 있으며, 시스템은 꼭 엄청나게 똑똑할 필요 없이 '사람들'이 그 역할의 일부를 대신해도 된다. 최근에, 그런 사례가 몇가지 보여서 모아봤다. 미국의 사례는 David Pogue의 최근 NY Times 컬럼과 블로그(6월 5일자 및 7월 10일자)에서 얻은 정보를 추가했다.
(1) Google Voice Search (GOOG-411)
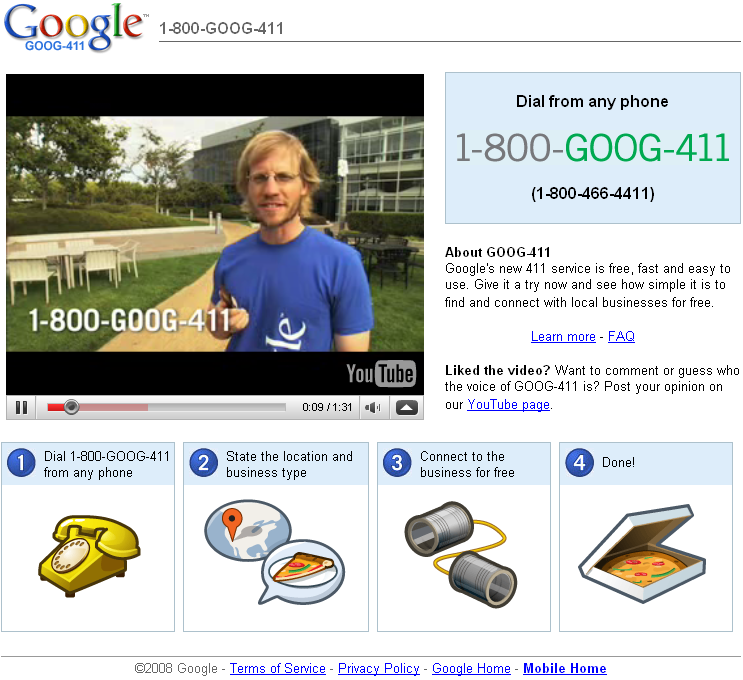
구글 정도의 검색능력을 갖춘 곳에서 음성검색을 한다면, 우선은 등골이 서늘한 느낌이 든다. "이거 이럼 더 할 일이 없는 거 아닌가..."하고 말이다. 하지만 다행히도(?), 구글의 음성검색은 411 서비스, 즉 전화번호부 검색 서비스와 약간의 부가 서비스에 그치고 있다. 위의 웹페이지 이미지에 설명되어 있듯이, 이 서비스의 사용 시나리오는 다음 대화(Pogue 컬럼에서 인용)에 잘 나와있다.
Google: “GOOG411. What city and state?”
Caller: “New York, New York.”
Google: “New York, New York. What business name or category?”
Caller: “Empire State Building.”
Google: “Empire State Building! Searching. Top listing: Empire State Building on Fifth Avenue. I’ll connect you.”
Caller: “New York, New York.”
Google: “New York, New York. What business name or category?”
Caller: “Empire State Building.”
Google: “Empire State Building! Searching. Top listing: Empire State Building on Fifth Avenue. I’ll connect you.”
즉, 지역 이름과 직종 분류를 거친 후에 나오는 결과 중에서 첫번째 아이템을 설명해주는 듯 하며, 결과가 여러 항목이 있을 경우라든가("다음, 다음, ..."), 음성인식 오류가 발생하는 경우에 대해서는 전혀 언급이 없다. 그래도 전화 연결 전에 "Details" 라고 명령해서 검색된 항목에 대한 자세한 정보 - 주소와 전화번호 - 를 확인할 수 있도록 한다던가, "Text message"라고 말해서 그 정보를 내 휴대폰에 SMS로 보낼 수 있는 기능이 있다던가 하는 것은 음성검색의 불안함 -_-;; 을 보완하는 훌륭한 부가 서비스라고 생각한다.
(사실 이 서비스에 대해서 가장 부러운 것은, Google에 voice researcher라는 사람이 일하고 있다는 거다. 물론 이 서비스 발표 후에 아무 업데이트가 없는 걸 보면 초큼 걱정도 되고 불안하기도 하고 그렇지만. ㅎㅎ )
(2) Yahoo oneSearch with Voice
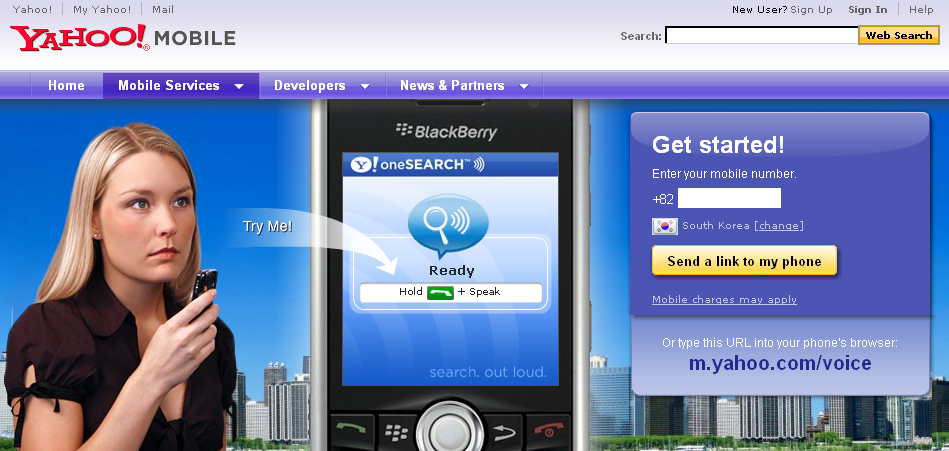
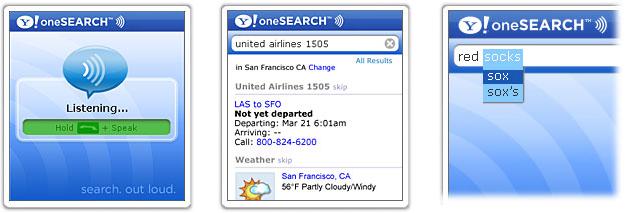
이러한 oneSearch의 앞단에 서버 기반 음성인식기를 넣은 것이 "oneSearch with Voice"라는 서비스다. 서버 기반 음성인식이므로 네트워크 비용이나 컴퓨팅 노력은 많이 들지만, 휴대기기에 embed 되어 있는 버전보다 그만큼 월등한 인식범위와 성능을 가질 수 있다. David Pogue의 경험을 그대로 인용하자면 (난 이 사람의 사업적 중립성에 대해서는 안 믿기 때문에 -_- ), 음성인식이라는 기술이 태생적으로 절대 인식할 수 없는 경우, 즉 고유명사를 제외하고는 대부분 올바르게 음성 검색어를 인식하고 검색결과를 제시했다고 한다.
사실 이 경우는 대화라고 하기가 좀 그렇다. 사용자가 말하는 것은 딱이 사람에게 하듯이 제시하는 문장이 아니라 검색어 조합에 가깝고, 그에 대한 '응답'도 대화체가 아닌 검색결과를 나열화면이다. 하지만 사용자가 뭔가를 음성으로 요청할 수 있다는 것은, 여전히 이 시스템이 단순한 정보입출력 이상의 인터랙션을 취하고 있다고 생각하게 만든다.
(3) 심심이
앞서서 간단하게 언급했던 대화 모델링의 기본은, 입력된 사용자의 대사에 적합한 응답을 시스템이 얼마나 잘 도출해 내느냐에 달려있다. 원칙적으로 하자면 상대방이 말한 말을 구문적으로는 물론 그 의미와 대화 맥락 상의 의도까지 이해한 후에, 일반적인 인간이 가지고 있는 방대한 사회적/자연과학적 상식과 해당 대화 주제에 대한 어느 정도의 지식을 바탕으로 응답을 도출하여 이를 올바른 문법적인 구조를 가진 문장으로 생성해내야 한다. ... 하지만 이건 이 길다란 문장 만큼이나 어려운 일이고, 실제로 최초의 성공적인 대화 시스템으로 꼽히는 MIT의 ELIZA는 물론 오늘날 매년 Turing Test에 도전하고 있는 대화 시스템들도, 그 주된 접근은 "상대방 대사의 대략의 구조에 대해서 미리 학습된 응답을 하는" 방식을 되도록 많이 모아서 사용하는 방식을 취한다. (인간은 그렇게 많은 대화경험을 언어적 구조를 파악함으로써 축약활용하지만, 컴퓨터는 그냥 엄청 방대한 DB를 운영함으로써 대신한다고 이해할 수 있겠다... 인간의 언어학습에 대한 이야기는 그냥 대충 넘어가기로 하고... ㅡ_ㅡ;; )
당연히 서비스가 오픈되지마자 불거진 사용자들의 오용 - 음담패설이나 욕설을 심심이에게 "가르치거나" 하는 - 을 막기 위해서, 현재의 심심이 사이트는 잘못된 대사-응답 쌍을 판단하게 하는 "재판소" 시스템을 만들어, 대화 학습은 물론 그 moderation까지도 네티즌에 의해 이루어지도록 하고 있다. 게다가 최근 시작한 듯한 "대화하기 2-1" 이라는 게임스러운 서비스는 아무래도 ESP Game의 아이디어를 따온 듯 한데, 아무래도 회원가입이 안 되니 확인할 길이 없다. ^^;;
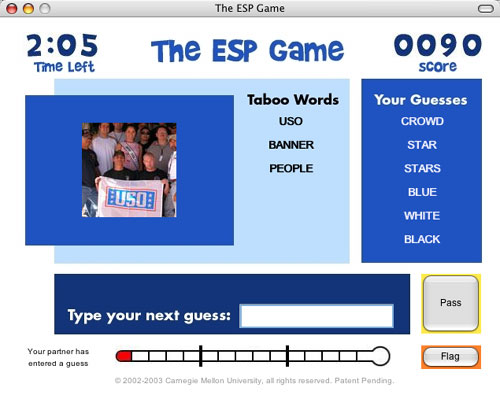
심심이는 작게 시작해서 참 끈질기게도 (ㅈㅅ) 명맥을 유지하고 있는 서비스인 동시에, 개인적으로는 매우 훌륭한 '공개적 대화시스템 구축 사례'라고 생각한다.
(4) ChaCha


(5) 엠톡
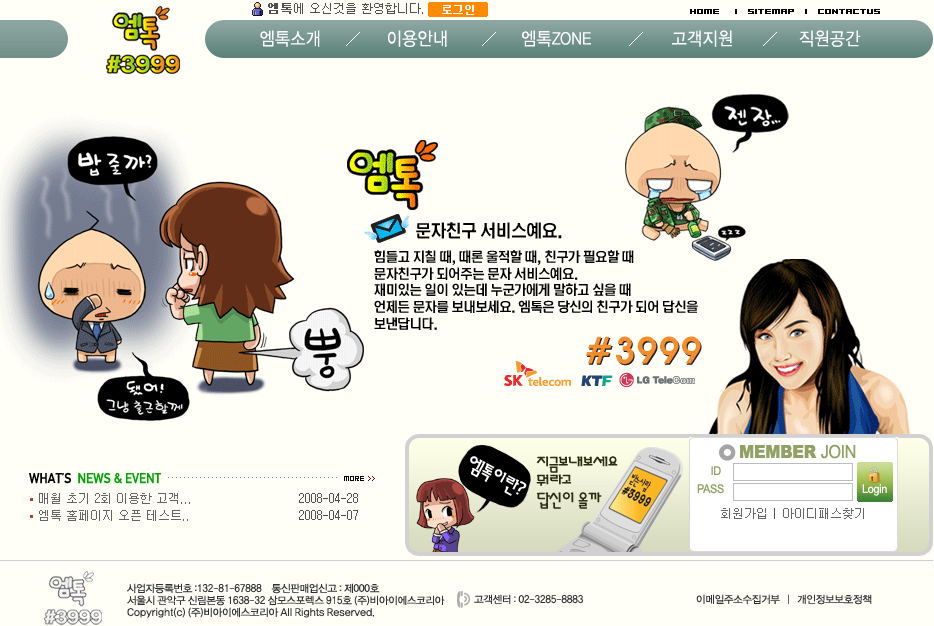
최근에 출퇴근 버스에 광고를 실으면서 내 관심의 대상이 된 "엠톡" 서비스는, 앞서 말한 ChaCha와 같은 개념의 서비스라고 할 수 있겠다. 광고의 내용만 보자면 "아무거나 물어보면 아무거나 대답해준다"는 컨셉은 그대로인 것 같지만, 사실 응답해주는 대상을 이렇게 헐벗은 젊은 여성으로 상정하고 있는 걸 보면 솔직히 성인전화방 대화 서비스의 사업확장으로 생각하고 있는 건 아닌지 심히 우려가 된다.


그게 이 "인공지능 대체 기술"의 한국적 사업모델이라면 어쩔 수 없겠지만, -_-;; 그래도 기왕이면 ChaCha의 그것처럼 네이버 지식인을 언제 어디서나 찾아서 요약해서 보내드립니다~라든가 하는 정보 서비스의 탈을 써주면 안 되겠니?
(6) Jott

이 영단어는 참 민망스런 발음 때문에 자주 쓰이지 않아서 다행이다 싶었는데, "Jott"이라는 서비스가 대놓고 시작하는 바람에 좀 자주 보게 될지도 모르겠다. ;ㅁ;
문자입력이 얼마나 어려운지는 몰라도, 이 서비스는 그걸 대신해줌으로써 인생을 쉽게 만들어준다는 게 모토인 듯 하다. 사용법에 대해서는 저어기 맨 위의 David Pogue의 컬럼에 붙은 동영상에서 잘 보여주고 있지만, 전화를 걸어 메모해 두고 싶은 내용이나 보내고 싶은 메시지를 말하면, 저쪽에서 그 내용을 누군가 받아적어서 텍스트 메시지나 이메일 등으로 보내준다는 컨셉이다. (아마 그 받아적는 누군가는 인도에나 필리핀에 앉아있을지도 모른다)
Jott: “Who do you want to Jott?”
Caller: “Myself.”
Jott: “Jott yourself.”
Caller: “Great idea for Act 2! Doing the laundry, Minna finds lipstick on her husband’s collar and sues the detergent company.”
Caller: “Myself.”
Jott: “Jott yourself.”
Caller: “Great idea for Act 2! Doing the laundry, Minna finds lipstick on her husband’s collar and sues the detergent company.”

직접 노트를 적거나 메시지를 쓰지 않고, 전화요금을 써가면서 다른 사람(기계나 시스템으로 치부한다 쳐도)에게 받아적게 한다는 것은 왠지 쉽게 이해가지 않는 사업모델이지만, 중세 유럽에서 편지나 책을 받아적는 직업이 존재했다거나 특별한 상황에서는 문자입력이 쉽지 않을 수 있다거나 하는 걸 생각해 보면 (아주 좁지만) 나름의 니즈는 있을 것 같기도 하다.
(7) ReQall
... 언제나 그렇지만, 이렇게 모아놓고 정리하다보니 또 제풀에 지쳐버렸다. 그래서 급 마무리. ㅡ_ㅡ;;; 어차피 최근에 자꾸 눈에 밟히는 서비스가 자꾸 쌓여서, 한데 모아놓고 싶었을 뿐이다. (먼산 '-')y~oO
반응형