재미있는 회사가 있다. 자주 가는 (거의 상주하지만) 동호회에 올라온 뉴스를 따라서 들어갔다가 알게 된 "이지인터페이스 EZ interface"라는 회사인데, 음성인식 기술을 독창적으로 개발한 사례가 상당히 돋보인다.
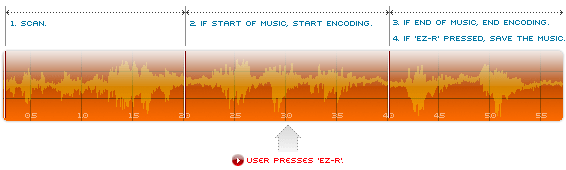
음성인식 기술이라고는 하지만, 사실 이 회사가 가지고 있는 특허 "음악 부분을 자동으로 선별해 저장하는 디지털 음악 재생 장치 및 그 방법"은 엄밀히 말해서 음성인식의 최초 전처리, 즉 입력된 음향(audio) 중에서 음성(voice)이 존재하는지 여부를 판정해서 구간을 정의하는(end point detecton) 과정만을 사용하고 있다. 문제는 이 방식을 기가 막히게 적합한 어플리케이션 - 라디오 방송에서 음악 부분을 찾아내서 저장하는 - 에 적용하는 생각을 했다는 것이다.
회사 웹사이트에 올라와 있는 설명과 위의 특허 청구항에 따르면, 이 기술은 라디오(물론, TV 음성이라고 안 되는 건 아닐 것이다) 방송 중 음성 부분을 제외하고 음악 구간을 인식해서 미리 녹음하고 있다가, 사용자가 '녹음' 버튼을 눌렀을 때 해당 음악을 파일로 저장해 주는 내용이다. 즉 듣고 있는 음악이 좋아서 '녹음'을 누르면 자신의 MP3 Player에서 들을 수 있는 거다.
얼핏 생각하면, 두가지 의문이 떠오를 수 있다.
우선은 "라디오에서 음악을 녹음한다니, 너무 구태의연한 '테이프 시대' 발상이 아닐까?" 라는 말이 나오는 건 자연스러운 일일 거다. 실제로 나도 소시적에는 라디오에서 나오는 음악을 녹음해 모아놓은 오디오 테이프를 십여개나 가지고 있었지만, 요즘은 그거 녹음할 시간에 인터넷 P2P에서 검색하는 게 훨씬 빠르고, 품질도 좋다고 생각한다. 하지만 우리가 P2P에서 다운 받을 수 있는 녹화된 TV 방송이나 MP3 음악 파일들은 사실 디지털 방송이나 디지털 매체에서 복사된 것이다. 디지털 방송의 잠재력까지 고려한다면, 방송에서 음악을 '다운로드'한다는 건 의외로 많은 문제를 해결할 수 있는 - 개인 감상을 위한 것으로 제한한다면 저작권 문제 없고, 음악 구하기 쉬우므로 사용자도 좋고, 라디오 시청율을 통한 광고수입이 있으므로 돈은 결국 방송국과 음악의 저작권자들에게 흘러갈꺼고 - 좋은 방법일 수 있다.
두번째 의문은, "음악과 멘트를 구분하는 게 음성인식기술이었나?" 라는 건데, 물론 "본부!"라든가 "키트! 빨리와!" 같은 음성명령을 인식하는 것과는 사뭇 차이가 있어 보이는 게 사실이다. 하지만 음성인식기술은 많은 요소기술들의 조합인데, 사실 그 하나하나도 상당 수준의 인공지능을 구현한 것이며, 나름의 쓸모를 찾아보면 괜찮은 어플리케이션이 나올 수 있다.
 이를테면 닌텐도의 NDS 게임기에서는 마이크에서 들어오는 소리가 어떤 음역에서 들려오는가를 봐서 음성인지 아닌지를 판단하고 있는데, 이걸 반대로 '전 음역에서 소리가 균등하게 들어오는지'를 판단해서 마이크를 입으로 부는 것을 인식하는 데 사용하고 있다. 이를 이용해서 게임에서는 화면 상의 구름이나 낙엽 등을 불어 날리거나, 비누방울을 부는 조작이 가능해졌으며, 독창적이면서도 매력적인 플레이를 제공하는 데에 큰 역할을 하고 있다.
이를테면 닌텐도의 NDS 게임기에서는 마이크에서 들어오는 소리가 어떤 음역에서 들려오는가를 봐서 음성인지 아닌지를 판단하고 있는데, 이걸 반대로 '전 음역에서 소리가 균등하게 들어오는지'를 판단해서 마이크를 입으로 부는 것을 인식하는 데 사용하고 있다. 이를 이용해서 게임에서는 화면 상의 구름이나 낙엽 등을 불어 날리거나, 비누방울을 부는 조작이 가능해졌으며, 독창적이면서도 매력적인 플레이를 제공하는 데에 큰 역할을 하고 있다.
따라서 이 새로운 기술 - EZ-R - 도 음성인식 요소기술을 적절히 활용하여 "음성인지 아닌지", 혹은 "음성 외의 음향이 얼마나 포함되어 있는지"를 판단함으로써 훌륭한 기능(음악만 녹음해 두는)을 구현한 사례라고 생각한다.
물론 모든 다른 인식 기술과 마찬가지로, 이 방식도 실용적으로는 적잖은 문제점을 가지고 있을 것이다. 이를테면 요즘 음악들은 워낙 구성이 다양해서, 음성과 음성 외 음향의 비중은 그야말로 천차만별이다. 즉 노래 앞이나 뒤, 혹은 노래 중에 랩이나 나레이션을 하는 경우에는 왠만해선 음악 구간을 잡는 데에 오류가 있을 수 밖에 없을 것이다.
또한, 방송의 진행자 역시 남녀노소 다양한 목소리 톤을 가지고 있으며, 개성이 강한 진행자일수록 일반적인 음성대역(100∼5000 Hz 라고들 한다)의 끄트머리를 오가는 발성을 하곤 한다. 그런 진행자를 좀더 포괄하려고 하면 할수록, 음성영역과 음악영역을 구분할 때의 오류는 심해질 것이다.
인식 기술 상의 오류 외에도, 예전에 테이프로 음악을 녹음해 모아본 사람은 누구나 알고 있듯이, 방송이라는 것이 음성과 음악을 정확히 구분할 수 있도록 제공되지 않는다는 것도, 근본적으로 이 서비스를 어렵게 하는 부분이 될 것이다.
하지만 이 모든 단점에도 불구하고, 2002년 기술 개발 및 특허출원에서부터 시작해서 필요한 기술을 필요한 만큼 찾아내서 훌륭한 적용사례를 만들어 주었다는 점에서, 이 회사에게는 감사와 박수를 보내고 싶다.
음성인식 기술이라고는 하지만, 사실 이 회사가 가지고 있는 특허 "음악 부분을 자동으로 선별해 저장하는 디지털 음악 재생 장치 및 그 방법"은 엄밀히 말해서 음성인식의 최초 전처리, 즉 입력된 음향(audio) 중에서 음성(voice)이 존재하는지 여부를 판정해서 구간을 정의하는(end point detecton) 과정만을 사용하고 있다. 문제는 이 방식을 기가 막히게 적합한 어플리케이션 - 라디오 방송에서 음악 부분을 찾아내서 저장하는 - 에 적용하는 생각을 했다는 것이다.
회사 웹사이트에 올라와 있는 설명과 위의 특허 청구항에 따르면, 이 기술은 라디오(물론, TV 음성이라고 안 되는 건 아닐 것이다) 방송 중 음성 부분을 제외하고 음악 구간을 인식해서 미리 녹음하고 있다가, 사용자가 '녹음' 버튼을 눌렀을 때 해당 음악을 파일로 저장해 주는 내용이다. 즉 듣고 있는 음악이 좋아서 '녹음'을 누르면 자신의 MP3 Player에서 들을 수 있는 거다.
얼핏 생각하면, 두가지 의문이 떠오를 수 있다.
우선은 "라디오에서 음악을 녹음한다니, 너무 구태의연한 '테이프 시대' 발상이 아닐까?" 라는 말이 나오는 건 자연스러운 일일 거다. 실제로 나도 소시적에는 라디오에서 나오는 음악을 녹음해 모아놓은 오디오 테이프를 십여개나 가지고 있었지만, 요즘은 그거 녹음할 시간에 인터넷 P2P에서 검색하는 게 훨씬 빠르고, 품질도 좋다고 생각한다. 하지만 우리가 P2P에서 다운 받을 수 있는 녹화된 TV 방송이나 MP3 음악 파일들은 사실 디지털 방송이나 디지털 매체에서 복사된 것이다. 디지털 방송의 잠재력까지 고려한다면, 방송에서 음악을 '다운로드'한다는 건 의외로 많은 문제를 해결할 수 있는 - 개인 감상을 위한 것으로 제한한다면 저작권 문제 없고, 음악 구하기 쉬우므로 사용자도 좋고, 라디오 시청율을 통한 광고수입이 있으므로 돈은 결국 방송국과 음악의 저작권자들에게 흘러갈꺼고 - 좋은 방법일 수 있다.
두번째 의문은, "음악과 멘트를 구분하는 게 음성인식기술이었나?" 라는 건데, 물론 "본부!"라든가 "키트! 빨리와!" 같은 음성명령을 인식하는 것과는 사뭇 차이가 있어 보이는 게 사실이다. 하지만 음성인식기술은 많은 요소기술들의 조합인데, 사실 그 하나하나도 상당 수준의 인공지능을 구현한 것이며, 나름의 쓸모를 찾아보면 괜찮은 어플리케이션이 나올 수 있다.
따라서 이 새로운 기술 - EZ-R - 도 음성인식 요소기술을 적절히 활용하여 "음성인지 아닌지", 혹은 "음성 외의 음향이 얼마나 포함되어 있는지"를 판단함으로써 훌륭한 기능(음악만 녹음해 두는)을 구현한 사례라고 생각한다.
물론 모든 다른 인식 기술과 마찬가지로, 이 방식도 실용적으로는 적잖은 문제점을 가지고 있을 것이다. 이를테면 요즘 음악들은 워낙 구성이 다양해서, 음성과 음성 외 음향의 비중은 그야말로 천차만별이다. 즉 노래 앞이나 뒤, 혹은 노래 중에 랩이나 나레이션을 하는 경우에는 왠만해선 음악 구간을 잡는 데에 오류가 있을 수 밖에 없을 것이다.
또한, 방송의 진행자 역시 남녀노소 다양한 목소리 톤을 가지고 있으며, 개성이 강한 진행자일수록 일반적인 음성대역(100∼5000 Hz 라고들 한다)의 끄트머리를 오가는 발성을 하곤 한다. 그런 진행자를 좀더 포괄하려고 하면 할수록, 음성영역과 음악영역을 구분할 때의 오류는 심해질 것이다.
인식 기술 상의 오류 외에도, 예전에 테이프로 음악을 녹음해 모아본 사람은 누구나 알고 있듯이, 방송이라는 것이 음성과 음악을 정확히 구분할 수 있도록 제공되지 않는다는 것도, 근본적으로 이 서비스를 어렵게 하는 부분이 될 것이다.
하지만 이 모든 단점에도 불구하고, 2002년 기술 개발 및 특허출원에서부터 시작해서 필요한 기술을 필요한 만큼 찾아내서 훌륭한 적용사례를 만들어 주었다는 점에서, 이 회사에게는 감사와 박수를 보내고 싶다.
반응형


