엊그제 아는 분이 재미있는 동영상이라면서 URL을 하나 보내줬다. 바로 G-Speak. 모르긴 몰라도 꽤나 주목받을 것 같은 완성도의 제스처 입력 장치다. 일단은 받은 동영상부터 연결하고 시작하자.
 영화 <마이너리티 리포트>가 개봉된 게 벌써 6년 전이다. 그 동안 수많은 Gesture UI와 Tangible UI, 그리고 가장 자격미달인 Touch UI까지 이 영화를 인용하며 자기 UI의 '혁신성'을 강조하곤 해왔다. (사실 영화야 2054년을 배경으로 했다고 해도 그것과 비교될 만한 걸 만든 건 왠지 혁신과는 거리가 있지 않나... -_-a ) 그런데, 이번엔 아예 영화 속의 동작기반 UI를 온갖 기술을 동원해서 똑같이 재현한 게 나온 거다. 이건 차라리 좀 혁신적이다.
영화 <마이너리티 리포트>가 개봉된 게 벌써 6년 전이다. 그 동안 수많은 Gesture UI와 Tangible UI, 그리고 가장 자격미달인 Touch UI까지 이 영화를 인용하며 자기 UI의 '혁신성'을 강조하곤 해왔다. (사실 영화야 2054년을 배경으로 했다고 해도 그것과 비교될 만한 걸 만든 건 왠지 혁신과는 거리가 있지 않나... -_-a ) 그런데, 이번엔 아예 영화 속의 동작기반 UI를 온갖 기술을 동원해서 똑같이 재현한 게 나온 거다. 이건 차라리 좀 혁신적이다.

이 프로토타입 시스템은 Oblong Industries이라는 작은 기술벤처 회사에서 개발한 것으로, 미국 방위산업체인 Raytheon Systems에서 자본을 댔다는 것 같다. 이 시스템에 대한 소개는 벌써 2006년 미국에서 방송을 탄 모양으로, CNN과 CBS에서 방송된 내용이 이미 유투브에 올라와 있다.
하나 더. (위의 것이 CNN, 아래 것이 CBS)
이제까지의 "마이너리티 리포트 방식" UI 들이 감히 하지 못한 게 데모 전에 실제로 영화의 장면을 보여주는 거 였는데, 저 화려한 실행장면에 비해서 그 일부만 구현했거나 온갖 보조장치가 덕지덕지 붙어 등장하는 기술데모는 초라하기 그지 없었기 때문이다. 그런데 이번엔 아예 보란듯이 나란히 보여주기까지... 아주 자신만만하다.
조금 감상적으로 씌여진 회사의 연혁 혹은 기술적 배경역사를 보면 알 수 있듯이, 이 회사의 대표는 바로 MIT Media Lab의 Tangible Media Group에서 Hiroshi Ishii 교수에게 수학했던 John Underkoffler이다. 말하자면 Tangible UI의 1세대라고 할 수 있겠는데, 그동안 그저 TUI의 태고적 흑백동영상 정도로 치부되던 1997년의 'Luminous Room' 동영상까지 덩달아 띄우고 있다. (이 기회에 개인적으로 좋아라 하는 I/O Bulb 개념에 대한 업계의 관심도 좀 살아나줬으면 좋겠는데 어쩌려나.)
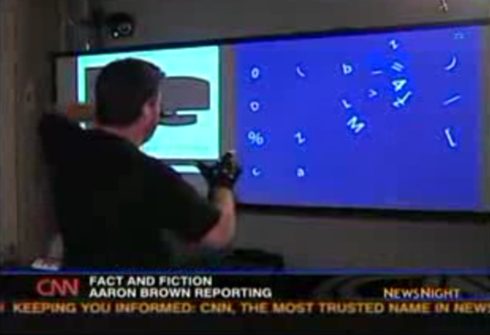
이 사람의 배경을 생각하면서 뉴스에 나온 영상들을 들여다보면, 대충 이 시스템은 AR 태그를 이용한 인식방법과 모션캡춰를 결합해서 돈을 아끼지 않고 만든 시스템으로 보인다. 최소한 3대의 프로젝터와 최소한 6대의 적외선 카메라, 그것도 카메라는 상당히 고해상도임이 틀림 없다. 그렇다고 시스템이 고정된 건 아니고, 그때그때 공간에 맞게 설치해서 calibration해서 사용할 수 있는 모양이다. 맨 앞의 동영상을 자세히 들여다보면 사용자 앞의 벽면에서 사용자를 노려보는 카메라만 5개다.
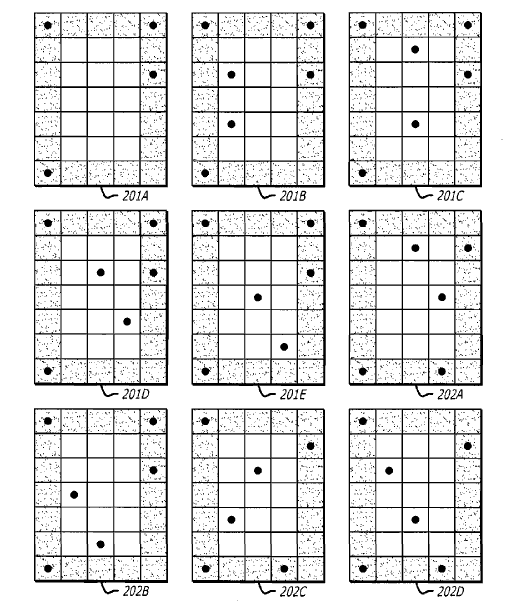
인식은 일반 모션캡춰에서 쓰이는 것보다 훨씬 작은 적외선 반사체를 양손의 장갑위의 손등과 엄지/검지/중지에 붙이되, 각각의 위치에 5x7의 격자를 놓고 35칸 중에서 5~6군데에만 반사체를 붙여 각각의 점을 구분하는 방법을 사용하고 있다. 널리 사용되는 AR Toolkit에서 흑백으로 인쇄된 종이를 사용하는 걸 응용한 듯.
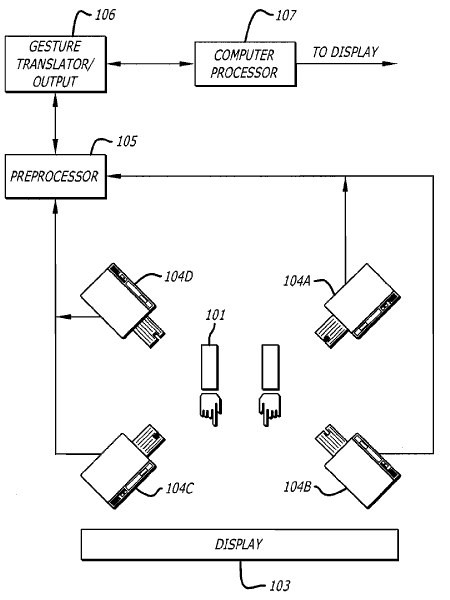
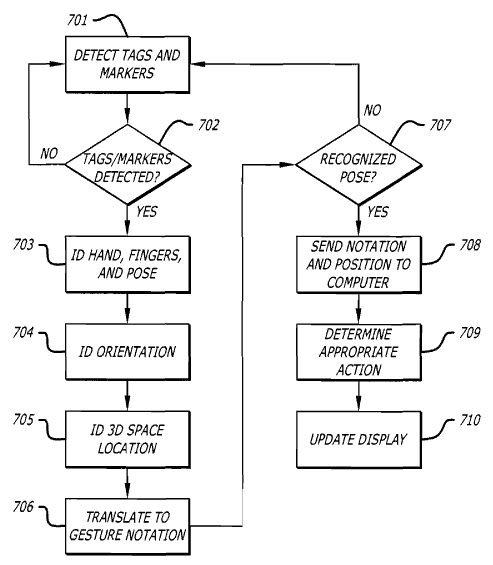
 문제는 정황 상으로는 비싼 군사용 고해상도 적외선 카메라와 엄청나게 빠른 컴퓨터를 사용했을 것 같은데, 카메라에 비친 저 카메라들과 광원의 모습은 전혀 적외선 카메라가 아니라는 거다. 일반적으로 적외선등(IR-LED Array)은 눈으로는 안 보이지만 보통 카메라로 찍으면 왼쪽 사진(2005년 용산 CGV의 영상인식 홍보설치물에서 촬영)처럼 보라색 광원으로 보이기 마련인데, 촬영된 동영상 어디에도 그런 건 없고 오히려 연두색 점광원만 보이고 있다. 흐음. 설마하니 자외선등 같은 건 아닐테고, 보안을 이유로 카메라에 적외선 필터라도 달게 한 걸까. 그렇다고 카메라의 빨강 LED가 녹색으로 보일 정도로 심한 필터링이 가능한지 모르겠다. ㅡ_ㅡa;;; 그 외에도 저 손가락 태그에 노란색/보라색 색이 칸칸이 다른 모양으로 칠해져 있는 이유가 딱이 설명되지 않는다. 뭔가 단순히 적외선 반사체의 배열로 AR tag를 대신해서 모션캡춰 장비에 연결시킨 것만은 아닌 모양.
문제는 정황 상으로는 비싼 군사용 고해상도 적외선 카메라와 엄청나게 빠른 컴퓨터를 사용했을 것 같은데, 카메라에 비친 저 카메라들과 광원의 모습은 전혀 적외선 카메라가 아니라는 거다. 일반적으로 적외선등(IR-LED Array)은 눈으로는 안 보이지만 보통 카메라로 찍으면 왼쪽 사진(2005년 용산 CGV의 영상인식 홍보설치물에서 촬영)처럼 보라색 광원으로 보이기 마련인데, 촬영된 동영상 어디에도 그런 건 없고 오히려 연두색 점광원만 보이고 있다. 흐음. 설마하니 자외선등 같은 건 아닐테고, 보안을 이유로 카메라에 적외선 필터라도 달게 한 걸까. 그렇다고 카메라의 빨강 LED가 녹색으로 보일 정도로 심한 필터링이 가능한지 모르겠다. ㅡ_ㅡa;;; 그 외에도 저 손가락 태그에 노란색/보라색 색이 칸칸이 다른 모양으로 칠해져 있는 이유가 딱이 설명되지 않는다. 뭔가 단순히 적외선 반사체의 배열로 AR tag를 대신해서 모션캡춰 장비에 연결시킨 것만은 아닌 모양.
그래서... 혹시나 해서 특허를 찾아보니 뭐 줄줄이 나온다. 저 앞의 뉴스에서는 원리가 비밀이라고 하더만, 딱히 비밀일 것도 없네 뭐. ㅡ_ㅡa;;; 대충 앞에서 설명한 것과 맞아 떨어진다. 2006년 2월에 출원했는데 여태 등록이 안 된 상태라서 그렇게 말한 걸지도 모르겠다. 어쨋든 특허만으로는 그냥 적외선 카메라 외에 특별한 걸 못 찾았다. 결국 이번 시스템의 기술적 비밀은 그저 막대한 (눈 먼) 군사자본이었던 거냐... OTL...
바로 전의 소니의 동장인식 게임 컨트롤러의 뉴스도 그렇고, 며칠 후에 올리려고 하는 뉴스도 있고... 요 며칠 참 동작기반 UI 관련 소식이 많다. 이번의 G-Speak가 많은 동작 UI 팬들의 마음을 설레게 할 만큼 영화 속의 환상을 잘 재현하고, 상상으로만 생각하던 동작인식 시스템을 그대로 구현한 건 사실이지만... 여전히 UI의 근원적인 질문을 안 할 수는 없을 것이다. "이게 쓰기 편할까?"
솔직히 동작인식.. 그것도 저렇게 양팔을 열심히 돌리고 움직여야 하는 UI가 사용자에게 편할 리가 없잖아. =_=;;; 테러리스트 잡으려는 일념으로 뭐 하나 검색하고 나면 완전 땀으로 범벅 되겠다. ㅋㅋ 게다가 동작 UI 해 본 사람은 안다. 동작명령 외우는 게 "가리키기"와 "잡기"를 제외하고는 (그런데 이것도 결국 마우스의 point and click이라 ;ㅁ; ) 얼마나 어려운지.
테러리스트 잡으려면 사실 데이터가 확보되는 게 우선이고, 데이터가 확보된 후에는 3D 마우스나 터치스크린 정도면 충분한 속도로 검색할 수 있을 것 같다. 굳이 저렇게 '달밤에 체조'를 하지 않아도 볼 수 있는 건 충분히 볼 수 있으텐데 말이지... 굳이 사용자의 손을 영상인식으로 추적하는 것보다, 수집된 영상데이터에서 수상쩍은 상황을 영상인식으로 골라내서 보통 PC 앞에 앉은 사람에게 최종확인을 맡기는 게 나을 것 같은 생각이 든다. ㅡ_ㅡa;; (아 물론 쫌 과장이다. 적외선 광점을 찾아내는 건 수상한 상황을 인식하는 것보다 몇천배 쉽다 ^^: )
이 프로토타입 시스템은 Oblong Industries이라는 작은 기술벤처 회사에서 개발한 것으로, 미국 방위산업체인 Raytheon Systems에서 자본을 댔다는 것 같다. 이 시스템에 대한 소개는 벌써 2006년 미국에서 방송을 탄 모양으로, CNN과 CBS에서 방송된 내용이 이미 유투브에 올라와 있다.
다음 날 아침에 추가:
뒤늦게 팀원이 지적해줘서 확인해 보니, 이 방송내용은 2006년 12월자 포스팅이다. =_=;; 결국 이때의 시스템을 개선(카메라 위치라든가 사용자 앞의 작업테이블로 이동하는 방식이라든가)해서 며칠 전에 맨 앞의 동영상을 올렸다고 보는 게 맞을 듯. 추가로 홍보비를 확보한 걸까. -_- 어쨋든 아래 뉴스 동영상에 기반한 내용들과 위 동영상 내용은 시기적으로 구분해서 참고하시길.
뒤늦게 팀원이 지적해줘서 확인해 보니, 이 방송내용은 2006년 12월자 포스팅이다. =_=;; 결국 이때의 시스템을 개선(카메라 위치라든가 사용자 앞의 작업테이블로 이동하는 방식이라든가)해서 며칠 전에 맨 앞의 동영상을 올렸다고 보는 게 맞을 듯. 추가로 홍보비를 확보한 걸까. -_- 어쨋든 아래 뉴스 동영상에 기반한 내용들과 위 동영상 내용은 시기적으로 구분해서 참고하시길.
하나 더. (위의 것이 CNN, 아래 것이 CBS)
이제까지의 "마이너리티 리포트 방식" UI 들이 감히 하지 못한 게 데모 전에 실제로 영화의 장면을 보여주는 거 였는데, 저 화려한 실행장면에 비해서 그 일부만 구현했거나 온갖 보조장치가 덕지덕지 붙어 등장하는 기술데모는 초라하기 그지 없었기 때문이다. 그런데 이번엔 아예 보란듯이 나란히 보여주기까지... 아주 자신만만하다.
조금 감상적으로 씌여진 회사의 연혁 혹은 기술적 배경역사를 보면 알 수 있듯이, 이 회사의 대표는 바로 MIT Media Lab의 Tangible Media Group에서 Hiroshi Ishii 교수에게 수학했던 John Underkoffler이다. 말하자면 Tangible UI의 1세대라고 할 수 있겠는데, 그동안 그저 TUI의 태고적 흑백동영상 정도로 치부되던 1997년의 'Luminous Room' 동영상까지 덩달아 띄우고 있다. (이 기회에 개인적으로 좋아라 하는 I/O Bulb 개념에 대한 업계의 관심도 좀 살아나줬으면 좋겠는데 어쩌려나.)
이 사람의 배경을 생각하면서 뉴스에 나온 영상들을 들여다보면, 대충 이 시스템은 AR 태그를 이용한 인식방법과 모션캡춰를 결합해서 돈을 아끼지 않고 만든 시스템으로 보인다. 최소한 3대의 프로젝터와 최소한 6대의 적외선 카메라, 그것도 카메라는 상당히 고해상도임이 틀림 없다. 그렇다고 시스템이 고정된 건 아니고, 그때그때 공간에 맞게 설치해서 calibration해서 사용할 수 있는 모양이다. 맨 앞의 동영상을 자세히 들여다보면 사용자 앞의 벽면에서 사용자를 노려보는 카메라만 5개다.
 |
 |
 |
인식은 일반 모션캡춰에서 쓰이는 것보다 훨씬 작은 적외선 반사체를 양손의 장갑위의 손등과 엄지/검지/중지에 붙이되, 각각의 위치에 5x7의 격자를 놓고 35칸 중에서 5~6군데에만 반사체를 붙여 각각의 점을 구분하는 방법을 사용하고 있다. 널리 사용되는 AR Toolkit에서 흑백으로 인쇄된 종이를 사용하는 걸 응용한 듯.
 |
 |
 |
그래서... 혹시나 해서 특허를 찾아보니 뭐 줄줄이 나온다. 저 앞의 뉴스에서는 원리가 비밀이라고 하더만, 딱히 비밀일 것도 없네 뭐. ㅡ_ㅡa;;; 대충 앞에서 설명한 것과 맞아 떨어진다. 2006년 2월에 출원했는데 여태 등록이 안 된 상태라서 그렇게 말한 걸지도 모르겠다. 어쨋든 특허만으로는 그냥 적외선 카메라 외에 특별한 걸 못 찾았다. 결국 이번 시스템의 기술적 비밀은 그저 막대한 (눈 먼) 군사자본이었던 거냐... OTL...
 |
 |
 |
바로 전의 소니의 동장인식 게임 컨트롤러의 뉴스도 그렇고, 며칠 후에 올리려고 하는 뉴스도 있고... 요 며칠 참 동작기반 UI 관련 소식이 많다. 이번의 G-Speak가 많은 동작 UI 팬들의 마음을 설레게 할 만큼 영화 속의 환상을 잘 재현하고, 상상으로만 생각하던 동작인식 시스템을 그대로 구현한 건 사실이지만... 여전히 UI의 근원적인 질문을 안 할 수는 없을 것이다. "이게 쓰기 편할까?"
솔직히 동작인식.. 그것도 저렇게 양팔을 열심히 돌리고 움직여야 하는 UI가 사용자에게 편할 리가 없잖아. =_=;;; 테러리스트 잡으려는 일념으로 뭐 하나 검색하고 나면 완전 땀으로 범벅 되겠다. ㅋㅋ 게다가 동작 UI 해 본 사람은 안다. 동작명령 외우는 게 "가리키기"와 "잡기"를 제외하고는 (그런데 이것도 결국 마우스의 point and click이라 ;ㅁ; ) 얼마나 어려운지.
테러리스트 잡으려면 사실 데이터가 확보되는 게 우선이고, 데이터가 확보된 후에는 3D 마우스나 터치스크린 정도면 충분한 속도로 검색할 수 있을 것 같다. 굳이 저렇게 '달밤에 체조'를 하지 않아도 볼 수 있는 건 충분히 볼 수 있으텐데 말이지... 굳이 사용자의 손을 영상인식으로 추적하는 것보다, 수집된 영상데이터에서 수상쩍은 상황을 영상인식으로 골라내서 보통 PC 앞에 앉은 사람에게 최종확인을 맡기는 게 나을 것 같은 생각이 든다. ㅡ_ㅡa;; (아 물론 쫌 과장이다. 적외선 광점을 찾아내는 건 수상한 상황을 인식하는 것보다 몇천배 쉽다 ^^: )
반응형



