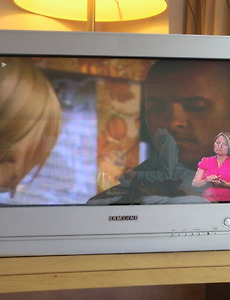
Human-Robot Interaction29 Tachikoma: My Private Dream of HRI 급고백. 나는 애니메이션 에 나온 "다치코마"라는 로봇을 좀 과하게 좋아한다. -_-;; 사무실 책상에는 작은 피규어 인형이 숨어있고, 집에는 조립하다 만 프라모델도 있다. 한동안 PC 배경으로 다치코마를 깔아두기도 했고. 애니메이션을 본 사람이라면 공감하겠지만, 인간적인 상호작용과는 전혀 동떨어지게 생긴 이 로봇(들)은 독특한 장난스런 말투와 동작, 그리고 무엇보다도 더없이 인간적으로 만드는 그 호기심으로 인해 그야말로 사랑스러운 캐릭터라고 할 수 있다. 하지만 내가 다치코마를 좋아하는 건 거기에 더해서, 에서 다치코마가 맡고 있는 '캐릭터' 때문이다. 다치코마는 '대체로 인간'인 (세부 설명 생략;;) 특수부대 요원을 태우고 달리거나, 그들과 함께 작전에 투입되어 어려운 일(이를테면, 총알받이)을 도.. 2008. 6. 13. Sharing Eyesight with Agent 이 블로그 최초의, 해외 특파원 소식이다. -_-;;; 출장 와서 동료들과 함께 아침을 먹으면서 (1인당 하나씩 시키기엔 양이 너무 많았다 -_-a ) 영국 TV를 보는데, 재미있는 걸 발견해서 이야깃꺼리가 됐다. BBC UK TV 와 Channel 4+1, E4+1 채널 중 몇 군데에서 청각장애인을 위한 수화를 뉴스나 드라마, 심지어 쇼프로에 이르기까지 제공해 주는데, 우리나라처럼 화면 한쪽에 동그란 영역을 따로 설정한 게 아니라 수화 narrator가 화면에 포함되어 있는 형태인 것이다. 게다가 특이한 것은, 대사가 없을 경우에도 배꼽에 손을 얹고 정면을 바라보고 있는 '차례' 자세가 아니라 아래와 같이 "같이 TV를 보는" 자세를 취하고 있는 게 이채롭다. 위와 같이 시청자와 같이 TV를 보다가, .. 2008. 5. 12. Ultimate Intelligence of Robot Vacuum Cleaner 예전 웹툰들을 들춰보다가, 지난 2006년 11월 28일자 와탕카를 보고 그냥 스크랩해 놓으려고 한다. 전체를 갖다놓는 건 요즘은 좀 위험할 것 같고, 그냥 로봇의 궁극적인 '인공지능'에 대해서 가장 인간적인 부분 - 게으름과 눈치 - 이 구현되었을 때의 로봇 청소기를 상상한 장면이 재미있다. (전체 스토리는 위 링크를 참조할 것) 로봇의 인공지능에 빗대어 인간의 "지능적인" 속성을 이야기하는 것은 웹툰에서도 자주 보이는 모습이다. 일전에 컴퓨터 대 인간의 카드 게임에서 인간이 인간 만이 가지고 있는 특징 - bluffing - 을 이용해서 컴퓨터를 이겼다는 뉴스와 맞물려서, 참 이런 로봇이 나온다면 나름대로 귀엽겠다는 생각이 든다. 물론 그 수준의 인공지능을 영화 이나 에서처럼 사용하지 않는다는 보장은.. 2008. 4. 21. Robot Equation (a tribute for Media Equation) 이라는 책이 있다. 번역본도 나온 것으로 알고 있고... 여하튼 이 책은 부제목에서 말하듯이 "어떻게 인간이 컴퓨터나 다른 새로운 미디어를 마치 사람인 것처럼 다루는가"에 대한 책이다. 이 책에서 말하는 new media에는 라디오나 TV도 포함하고 있고, 음성입출력을 사용하는 기계라든가 화면 상의 의인화된 에이전트 캐릭터에 대해서도 언급하고 있다. 그림이 없기 때문에 많은 상상력을 동원해야 하는 읽기 힘든 글이지만, (저자인 Clifford Nass 교수와 대화한 적이 한번 있는데, 그때의 경험과 비슷하다. 어찌나 빠르게 말로만 이야기하는지! -_-;; ) 어찌 보면 당연할 내용을 하나하나 실험을 통해서 밝혀주었다는 점에 대해서는 머리를 조아리고 받들어야 할 참고문헌이라고 생각한다. 이 책 - Medi.. 2008. 4. 13. Machine Talks, Machine Sings, and ... '노래하는 TTS' ... 그런 이름의 연구과제를 어깨너머로 본 적이 있다. (TTS는 Text-To-Speech, 즉 음성합성이라는 뜻이다) 당시 소속되어 있던 연구실 뿐만 아니라 국내에서만도 몇몇 학교와 연구기관에서 연구하던 주제였다. 어느 정도 알아들을 수 있는 걸음마 수준의 음성합성기였지만, 떡잎부터 보였던 문제 중 하나는 그 '소름끼치는 목소리'였다. 분명 100% 기계적으로 합성한 초기의 음성합성 방식이 아님에도 불구하고, 사람 목소리 중에서 다양하게 사용할 수 있는 '중립적인' 음원을 중심으로 sampling하다보니 아무래도 강약도 높낮이도 없는 건조한 목소리가 되기 마련이고, 그렇게 합성된 음성에는 "공동묘지에서 들리면 기절하겠다"든가 "연변 뉴스 아나운서가 있다면 이렇지 않을까"라든가 하.. 2008. 2. 13. Computer Vision may Fail for a While 영상인식은 가장 기대되는 HTI 관련 기술 중 하나이다. 예전에 어느 세미나에선가 발표자가 "미래의 모든 기술은 영상인식을 바탕으로 할꺼다"는 말에 크게 공감한 적도 있었으니까. 물론 여기서 영상인식은 2차원 공간에서의 정보처리에 대한 것이고, 그 논리대로라면 멀티터치 방식도 영상인식 기술을 활용한 게 된다. 어쨋든, 이 영상인식 기술들이 '컴퓨터 편한 기준에 의해' 평가되고 개발되었기 때문에 인간과 같은 능력을 가질 수 없을 거라는 연구가 MIT의 신경과학자에 의해서 발표되었다고 한다. 이를테면 다음과 같은 그림에서, 사람은 이 그림들이 모두 같은 물체(자동차)를 다른 각도와 크기로 찍은 사진이라는 것을 알지만, 영상인식으로는 이러한 것을 알 수가 없다는 것이다. 사실 이러한 문제 제기가 과히 새로운 .. 2008. 1. 28. Agent, Blamed until the Last Day (of Bill Gates) 이번 CES 2008 행사는 왠지 큰 UI 이슈 없이 지나가는 것 같다. 전례없이 크고 얇은 디스플레이 장치가 등장하기도 하고, 온갖 규약의 온갖 네트워크 장비가 등장해서 Ubicomp 세상을 비로서 당당하게 열어젖히고 있기는 하지만, 딱이 UI라고 할 수 있는 건 그다지... 자주 가는 웹사이트들에서 파악하기로는, 일전에도 언급했던 Motorola E8이 공식 발표되었다는 것 정도가 그나마 관심이 있달까. 그러다가, 며칠 전 있었던 Bill Gates의 기조연설이 Microsoft에서 은퇴하는 그의 마지막 기조연설이었고, 그걸 나름 기념하기 위해서 아주 재미있는 동영상이 하나 소개된 걸 알게 됐다. ㅋㅋㅋ... 재미있는 동영상이다. 이제까지는 좀처럼 스스로를 우스개꺼리로 삼지 않던 빌 게이츠답지 않은,.. 2008. 1. 8. IBM's Next Five in Five IBM에서 "앞으로 5년간 우리 생활을 바꿀 5가지 혁신"을 발표했다. ... 이런 걸 볼 때마다, UI 라는 건 (디자인도 그렇고) 그다지 세상을 바꾸지 않는구나~ 라는 생각이 우선 드는 건 사실이지만, 그래도 간접적으로나마 관련있는 주제가 있다는 건 주목해둬야 할 것 같다. 이미 Don Norman은 에서 자동운전 auto cruise control 차량의 UI 문제를 자주 언급하고 있는데, 사실 자동차는 여러가지 측면에서 Intelligent UI의 선진사례가 되어줄 것이다. Intelligent UI의 상용화를 연구하다보면, 우리가 주변에서 사용하고 있는 물건들 - 그 중에 어떤 것은 사용자의 생명을 책임지고 있음에도 불구하고 - 이 얼마나 값싼 마이크로 칩을 이용한 단순한 알고리듬으로 운용되고 .. 2008. 1. 2. Things That Think, NOW. 제목의 'TTT' 라는 문구는 MIT Media Lab.의 유명한 (아마도 가장 유명한) 연구 컨소시엄의 이름이다. 웹사이트를 찾아보면 이 프로젝트는 1995년에 시작되었으며, "디지털로 인해서 기능이 강화된 물건과 환경을 만드는" 데에 그 목적을 두고 있다. Hiroshi Ishii (Tangible Media Group), Roz Picard (Affective Computing Group) 등 UI 하는 입장에서 유난히 관심이 가는 교수들이 director를 하고 있고, 그 외에도 내가 이름을 알 법한 MIT의 교수들은 모두 참여하고 있는 것 같다. (내가 이름을 알 정도라는 것은, 그만큼 UI design에 가깝거나, 아니면 대외활동에 열을 올리고 있는 교수라는 뜻이니.. 각각 어느 쪽으로 해석할.. 2007. 11. 26. '캐나다 최초의' 안드로이드. 혹은 '세계 최초의...' '캐나다 최초'의 안드로이드를 만든 중국계(아마도) 연구자가, 사실은 로봇 연구에 있어 '세계 최초'의 업적(?)을 세웠음이 드러나 구설수에 오르고 있다. 우선 닥치고 동영상 한편. 바로 "세계 최초로 성폭행 당한 로봇"이 된 거다. ㅡ_ㅡ;;; 일반적으로 많은 사람들이 기가 막혀하는 바로 이 장면. 어떻게 생각하는가? 이 동영상을 처음 접한 engadget 에서는, 기사 본문은 물론이고 리플에 이르기까지 이 연구자의 몰염치한 행위와 뻔뻔한 인터뷰 내용에 대하여 분노하는 글로 가득하다. 이제까지 많은 로봇 - 안드로이드, 휴머노이드, ... 뭐든 - 이 인간의 일반기준에 의하자면 신체적인 장애를 가지고 있었음에도, 굳이 이 연구자에 한해서만 "장애인 로봇을 만들어놓고 그것도 모자라서 성폭행까지...!!!.. 2007. 11. 22. 이건 게임도 아니고 현실도 아니여~ (게임↔현실이라는 구분은 일단 넘어가기로 하고) 닛산에서 꽤 오래전에 광고하던 주변환경 모니터(Around View Monitor)를 완성한 모양이다. 일본에선 10월에 Elgrand, 미국에선 12월에 Infiniti EX35에 탑재되어 출시된다고 하고. 4개의 180방위 카메라를 사용한다고 한다. 원전: http://www.engadget.com/2007/10/12/nissans-around-view-arrives-in-the-us-december/ 이런 걸 진짜 만들어냈다는 것도 참 대단하지만, 동영상도 감동. -_ㅠ VR이니 AR이니 말들은 많았지만, 실제로 이렇게 하나둘 상용화되어가는 걸 보면, 게다가 그나마 몇년이나 걸쳐서 이렇게 결국 완성해낸 사람들을 보면, 참 말보다 행동이랄까..하는 점이.. 2007. 10. 13. <UI Breakthrough> by Don Norman 이 할아버지의 행보가 나는 불안불안하기만 하다. 심리학자로서 나름대로 경력을 쌓다가 난데없이 일상의 물건들에 대한 소고를 정리해서 책으로 내면서 (the psychology of everyday things) 딱이 이론이 없던 UI 업계에 영웅으로 등장하더니, 그 후로도 잇달아 UI 업계를 효용성(things that make us smart)에서 기술(invisible computer)로, 다시 감성(emotional design)으로 뒤흔드는 저서를 연달아 발표했다. 그 와중에 심리학계에서는 다른 사람의 연구를 껍데기만 인용해서 민중을 현혹시키는 이단아로 불리고 있었고... 심리학자에서 UI 컨설턴트로의 변화에서 예측할 수 있었어야 하겠지만, 최근 KAIST에서 있었던 이 할아버지의 발언 - "사용하.. 2007. 9. 27. 이전 1 2 3 다음 반응형